How to generate text?
🤗 transformers를 활용하여 language generation의 다른 decoding methods를 사용해보자!




- Introduction
- Using different decoding methods for language generation with Transformers
- GenerationMixin 뜯어보기
Introduction
최근 몇 년 동안 OpenAI의 GPT-2 모델과 같이 수백만 개의 웹 페이지에서 훈련된 large-scale transformer 기반 언어 모델의 등장으로 open-ended language generation에 대한 관심이 높아졌습니다. Conditioned open-ended language generation의 결과는 굉장히 인상적입니다.
2017년에 transformer가 등장한 이래로 아키텍쳐를 수정하는 방법 및 방대한 unsupervised 학습 데이터(self-supervised를 위한)들이 있지만 더 나은 디코딩 방법(better decoding methods) 또한 중요한 역할을 했습니다.
이 블로그 포스트는 다양한 디코딩 전략에 대한 간략한 개요를 제공하고 더 중요한 것은 유명한 🤗 transformers 라이브러리를 사용하여 아주 적은 노력으로 이를 구현할 수 있는 방법을 보여줍니다!
- jinmang2: 또한 제 블로그 포스팅에서 여러분들은 🤗 transformers에서 Decoding methods가 어떻게 구현되어 있는지도 알 수 있습니다.
본 게시글에서 다루는 모든 기능들(functionalities)은 모두 auto-regressive language generation(더 자세한 내용은 Jay Alammar님의 포스팅을 확인해주세요)에 사용할 수 있습니다. auto-regressive란 간단히 말해 아래 가정을 기반으로 둔 방법론입니다.
Assumption
==========
The probability distribution of a word sequence can be decomposed into
the product of conditional next word distributions.word sequence, 즉, 단어로 이루어진 수열(문장이라고 이해하시면 됩니다)은 다음 단어가 나올 조건부 분포들의 곱으로 분해가 가능하다라는 전제를 깔고 있습니다.
수식으로 보겠습니다.
$$P(w_{1:T}|W_0)=\prod_{t=1}^{T}P(w_t|w_{1:t-1},W_0),\;\text{with}\, w_{1:0}=\emptyset$$
- $W_0$은 initial context word sequence
- $T$는 문장의 길이입니다.
- patrick님 포스팅 본문에서는 생성된 문장의 길이를 의미하시는 것 같습니다. 생성은 단어(혹은 토큰) 단위로 길이가 1씩 늘어나기 때문에 on-the-fly라는 표현을 사용하신 것 같습니다.
- Timestep $t$가 $T$가 되면? 문장을 전부 분해했다는 뜻이겠죠?(conditional next word dists.로) 이 때는 $P(w_t|w_{1:t-1},W_0)$에서
EOS토큰이 생성됩니다.-
EOS는 End of Sentence(혹은 Sequence)의 약자로 문장의 끝을 의미합니다.
-
이제 가장 중요한 네 가지 decoding 방법에 대하여 소개해드리도록 하겠습니다.
블로그 포스팅의 예시를 보셔도 좋고 아무래도 한국어로 번역된 포스팅이기 때문에 한국어 언어 모델로 예시를 들어드리는 것이 보기 좋을 것 같습니다. 이에 대한 세팅을 수행하죠.
- tensorflow는 사용하지 않습니다.
!pip install -q git+https://github.com/huggingface/transformers.git
예시에서 사용할 모델은 SKT에서 개발한 KoGPT2이며 자세한 설명은 아래 링크를 참고해주세요.
간략한 소개는 다음과 같습니다.
- Vocab size: 51,200
- 이모지, 이모티콘 등을 추가하여 해당 토큰의 인식 능력 개선
- unused token을 100개 사용하여 필요한 task에 따라 자유롭게 정의 가능
- metaspace는
▁
| Model | # of params | Type | # of layers | # of heads | ffn_dim | hidden_dims |
|---|---|---|---|---|---|---|
kogpt2-base-v2 |
125M | Decoder | 12 | 12 | 3072 | 768 |
- 사용한 데이터는 한국어 위키 백과, 뉴스, 모두의 말뭉치 v1.0, 청와대 국민청원 등 다양한 데이터
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path_or_name = "skt/kogpt2-base-v2"
tokenizer = AutoTokenizer.from_pretrained(model_path_or_name, force_download=True)
model = AutoModelForCausalLM.from_pretrained(model_path_or_name, force_download=True)
tokenizer # Rust로 구현된 `Fast`한 tokenizer
tokenizer.tokenize("근육이 커지기 위해서는")
model.__class__.__name__ # AutoModelForCausalLM으로 GPT2의 CLM class 호출
num_of_parameters = sum(p.numel() for n, p in model.named_parameters())
print(f"{num_of_parameters}") # 125M
LMHeadModel(Causal-LM을 하기 위한 모델)은 크게 세 파트로 나뉘어져 있습니다.
(1) word token/position embedding
- 인코딩된 word sequence에 대해 embedding value를 계산합니다.
- 단어(혹은 토큰)의 뜻을 word token embedding으로,
- 단어(혹은 토큰)의 위치를 word position embedding으로 벡터화해줍니다.
- position embedding의 경우 layer에 해당 정보를 넣어주는 경우도 있지만 (relative position embedding) 해당 포스팅의 범주를 넘어서기 때문에 향후 소개하도록 하겠습니다.
Note that: 아래 코드는 GPT2 script에서 발췌한 코드입니다! wte, wpe를 구하는 것은 model by model이에요!"
word_sequence = "근육이 커지기 위해서는"
inputs = tokenizer(word_sequence, return_tensors="pt")
input_ids = inputs["input_ids"]
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
input_ids
실제로 모델 인풋에 어떻게 들어가나 확인해보죠.
import inspect
# input_ids, attention_mask, token_type_ids, position_ids가 중요해요
# forward와 __call__의 관계는 `torch.nn.Module`을 상속받아서 그래요
# 이건 다음 학습 기회로!
inspect.signature(model.transformer.forward).parameters
위에서 확인한 것 처럼 position type ids를 직접 입력에 넣어줄 수도 있지만 이번엔 직접 만들어줄게요! (실제로 source code에서 position_ids가 None이면 아래처럼 만들어줘요)
import torch
position_ids = torch.arange(0, input_shape[-1], dtype=torch.long)
position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
position_ids # 네 개의 토큰에 대한 위치 정보
Word token embedding의 경우 vocab의 수만큼 vector가 정의되어 있어야 합니다.
하지만 Word position embedding의 경우 tokenizing의 결과로 나온 토큰의 수로 매핑이 되기 때문에 미리 max_length를 정해둬요. KoGPT2의 경우엔 1,024네요!
위와 같은 이유로 wte와 wpe의 matrix shape은 다릅니다!
- GPT2는 absolute position embedding을 사용하기 때문이에요!
- Transformer의 SInusoidal encoding을 사용하면 extrapolate를 할 수 있기 때문에 저런 위치 고정 문제는 생기지 않겠죠!
(
model.transformer.wte, # vocab_size X hidden_dim
model.transformer.wpe, # max_position_length X hidden_dim
)
inputs_embeds = model.transformer.wte(input_ids)
position_embeds = model.transformer.wpe(position_ids)
hidden_states = inputs_embeds + position_embeds
hidden_states.shape # (batch_size, sequence length, hidden_dim)
print(f"n_layers: {len(model.transformer.h)}")
for i, block in enumerate(model.transformer.h):
outputs = block(hidden_states)
hidden_states = outputs[0]
hidden_states = model.transformer.ln_f(hidden_states) # final layer norm
hidden_states.shape
lm_logits = model.lm_head(hidden_states)
lm_logits.shape # (batch_size, sequence_length, vocab_size)
이렇게 세 가지 과정을 거쳐서 모델은 Causal-LM, 이전 단어들로부터 다음 단어를 예측하는 Conditional next word distribution을 학습하게 됩니다. 추론에서는 이제부터 소개할 decoding 방법론으로 계산된 확률을 어떻게 사용하느냐 이것이 갈리겠지요!
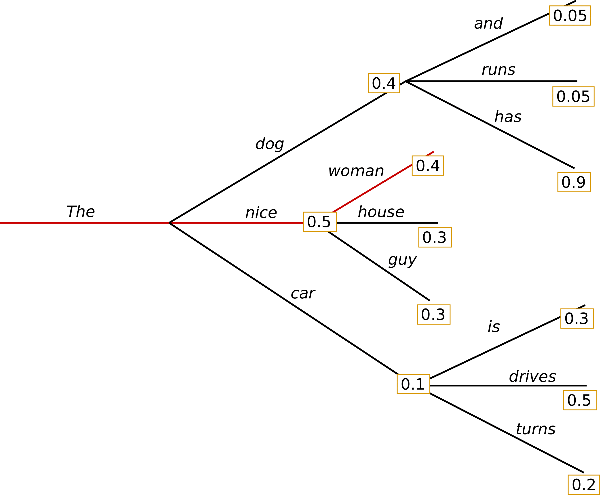
The 라는 단어로부터 시작하여 알고리즘은 탐욕적으로(greedily) 다음으로 올 단어로 가장 높은 확률을 가지는 nice를 선택합니다. 이렇게 종료 시점까지 탐욕적으로 선택하면 위의 예시에서 최종적으로 생성된 word sequence는 (The, nice, woman)이 될 것입니다.
- 해당 word sequence가 나올 확률은 $0.5 \times 0.4 = 0.2$로 꽤나 높습니다.
구현 상세는 제가 뜯어보며 알아낸 정보를 다루는 Chapter 2에서 다루고 huggingface에서 어떻게 사용할 수 있는지 알아봅시다.
input_ids = tokenizer.encode("근육이 커지기 위해서는", return_tensors="pt")
# CLM으로 문장을 생성 (output length가 128에 도달할 때 까지)
greedy_output = model.generate(input_ids, max_length=128)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
오... 잘 생성해냈군요 ㅎㅎ. 하지만 자세히 보면 규칙적인 생활습관이 중요하다고 내용을 반복하는 문제가 보이는군요...!
이는 일반적으로 natural language generation에서 일반적인 문제이며 greedy search, beam search와 같은 maximization 기법에서 훨씬 더 심하게 발생됩니다.
Greedy search의 주된 단점은 낮은 확률 사이에 숨겨진 높은 확률의 단어를 놓치는 것
입니다. 위의 예시에서도 (The, dog, has)를 놓쳤죠. 이 문장은 사실 $0.4 \times 0.9 = 0.36$으로 위의 문장보다 조금 더 가능성이 있는 문장입니다.
고맙게도 beam search가 위 문제를 조금 덜어줍니다!
- alleviate입니다. 해결해주지는 않습니다...
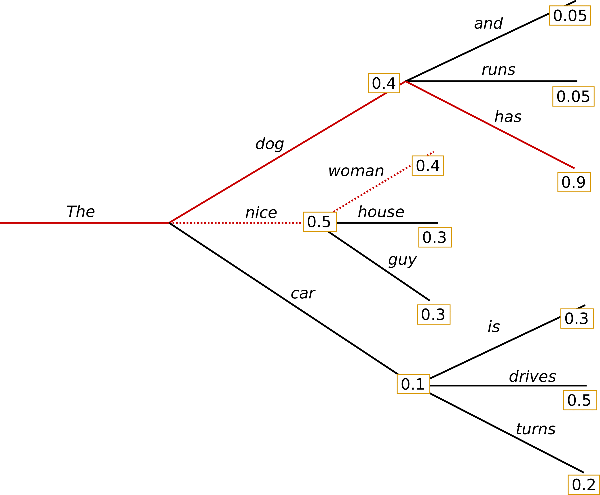
Time step 1에서 가장 가능성이 높은 가설은 (The, nice)로 확률이 0.5, 그 다음으로 높은 확률을 보이는 가설은 (The, dog)로 확률이 0.4입니다. greedy search에서는 top-1만 선택했기 때문에 아래 가설이 무시되었지만 beam search에서는 num_beams만큼 가설을 유지하기 때문에 두 번째로 높은 확률을 가지는 가설 (The, dog)를 기각하지 않고 유지합니다. (어떻게 유지하는지는 Ch2)
Time step 2에서 (The, dog, has)는 0.36의 확률을 가지는 가설이고 greedy search의 결과였던 (The, nice, woman)은 0.2의 확률을 가지는 가설입니다. 어때요 확률이 뒤집혔죠?
Beam search는 항상 greedy search보다 높은 확률로 output sequence를 찾아줍니다. 하지만 가장 가능성이 있는 출력을 찾는 것은 보장되지 않죠. (sub-optimal solution)
transformers에서의 예시를 봅시다!
beam_output = model.generate(
input_ids,
max_length=128,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
음... 하지만 출력에 여전히 동일한 word sequence의 반복이 포함되는 군요...
이에 대한 간단한 해결책은 Paulus 연구진이 도입한 n-grams penalty(a.k.a word sequences of n words)를 사용하는 것입니다.
- A Deep Reinforced Model for Abstractive Summarization, Paulus et al. (2017)
- OpenNMT: Open-Source Toolkit for Neural Machine Translation, Klein et al. (2017)
가장 흔한 n-grams penalty는 이미 본 n-gram을 생성할 수 있는 다음 단어의 확률을 수동으로 0으로 설정하여 n-gram이 두 번 다시 나타나지 않도록 하는 것입니다.
no_repeat_ngram_size를 2로 설정하여 동일한 n-gram이 2번 이상 반복되지 않도록 수정해보죠!
beam_output = model.generate(
input_ids,
max_length=128,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
반복의 문제는 해결되었군요! (다만 갑분 현대자동차... 저는 다만 근육이 커지는 방법을 알고 싶었습니다만...)
다만 patricks에 따르면 n-gram penalty는 주의해서 사용해야 합니다. 예를 들어 New York 시에 대해 생성된 기사는 2-gram penalty를 사용하면 전체 텍스트에서 도시 이름이 한 번만 나타나기 때문입니다.
Beam search의 또 다른 중요한 기능은 생성 후 top beams를 비교하고 목적에 가장 잘 맞는 generated beam을 선택할 수 있다는 점입니다.
🤗 transformers에서 num_return_sequences 매개변수를 세팅하면 위의 작업을 수행할 수 있습니다.
-
num_return_sequences는 항상num_beams보다 작아야 합니다.
beam_outputs = model.generate(
input_ids,
max_length=128,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# now we have 3 output sequences
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
decoded_text = tokenizer.decode(beam_output, skip_special_tokens=True)
print(f"{i}: {decoded_text}", end="\n\n")
음... 반환받았지만 각 beam들이 크게 다르지 않습니다.
Open-ended generation에서 최근에 beam search가 최선이 아닐 수 있다는 몇 가지 이유가 제기되었습니다.
- Beam search는 기계 번역이나 요약같이 원하는 생성의 길이가 어느 정도 예측 가능한 작업에서 매우 잘 동작합니다. 그러나 원하는 출력의 길이가 크게 달라질 수 있는 open-ended generation의 경우(대화 혹은 story 생성) 그렇지 않습니다.
- 위에서 확인했듯 beam search는
repetitive generation에 취약합니다. 이는 n-gram 혹은 다른 penalty로 적절히 조정하기가 어렵습니다. - Holtzman에 따르면, High quality human language는 다음 단어가 가장 높게 올 확률 분포를 따르지 않습니다. 즉 인간은 생성된 텍스트가 우리를 놀라게 하고(surprise) 지루하거나(boring) 예측할 수 없기를(not to be predictable) 원합니다. 저자는 BeamSearch로 생성된 text가 덜 놀랍다는 것을 아래 plot으로 보여줍니다.
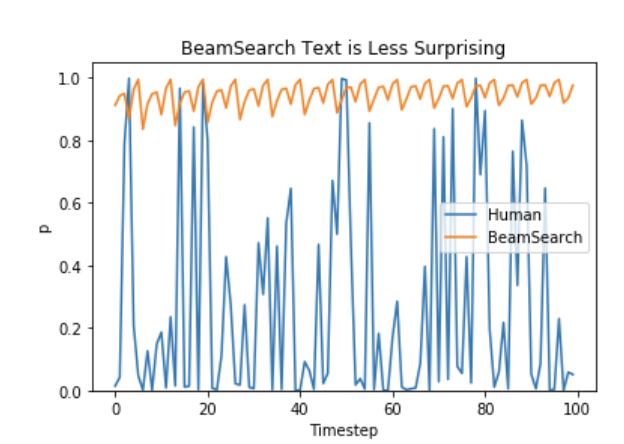
자, 지루한 text는 그만 생성하고 randomness를 도입합시다 :)
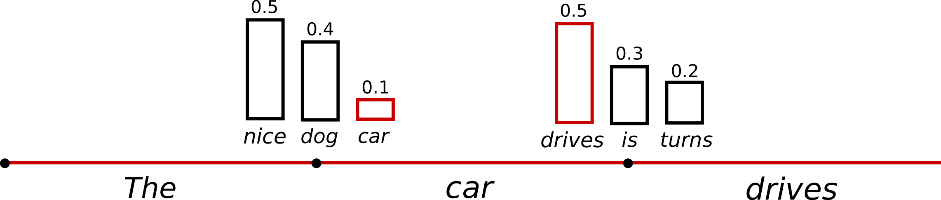
샘플링을 사용한 언어 생성은 더 이상 결정적이지 않습니다.
- Maximization 기법(greedy, beam)은 가장 높은 확률을 가지는 가설만을 택했습니다.
단어 car은 beam을 3만큼 늘리지 않으면 이전 maximization 기법에서는 어떠한 경우에도 절대로 채택되지 않습니다. 하지만 정말 낮은 확률로 조건부 확률 분포 $P(w|`the`)$에서 단어 car가 추출될 수 있으며 다음 단어인 drives, is, turns가 조건부 확률 분포 $P(w|`the`,`car)$에서 추출될 것 입니다.
🤗 transformers에서 do_sample 옵션을 활성화시키고 top-k sampling을 비활성화시켜서 위를 구현할 수 있습니다.
import random
import torch
import numpy as np
def set_seed(seed: int = 42):
"""Seed fixer (random, numpy, torch)
Args:
seed (:obj:`int`): The seed to set.
"""
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if use multi-GPU
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed()
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=128,
top_k=0,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
어... 내용은 차치하고 반복 문제는 안보이네요! 하지만 표현이 이상합니다.
- 교정이 어렵다고 하여 하는 것이다.
- 특히 교정에 시간을 투자하다
- 보면 교정수술에 욕심이 생시게 되는 즉이 있다
이는 word sequence를 sampling할 때 생기는 큰 문제입니다. 모델은 종종 일관성없이 횡설수설합니다.
위를 해결할 트릭은 분포 $P(w|w_{1:t-1})$을 sharp하게 만드는 것입니다.
- 가장 높은 확률을 가지는 단어의 likelihood를 높이고
- 가장 낮은 확률을 가지는 단어의 likelihood를 낮추는 것
위 트릭은 softmax의 temperature라고 불립니다.
temperature를 적용한 예시에 대한 시각화입니다.
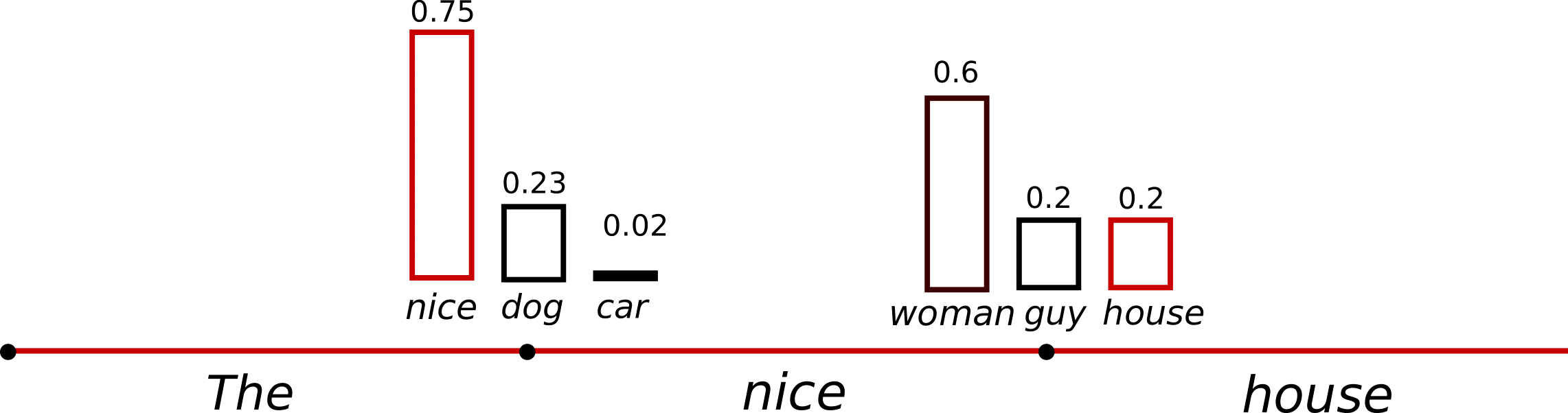
temperature를 적용하기 전에는 $P(w|`the`)$에서 car가 뽑힐 확률이 0.1이었지만 지금은 0.02입니다. 낮아진 만큼 뽑히기는 더 힘들겠죠?
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=128,
top_k=0,
temperature=0.7,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Maximization의 결과와 유사하면서 반복은 안하고 다른 내용까지 추가되었습니다! (물론 근육과는 아직도 관련이 적습니다... 그래도 일관성은 개선되었군요.)
temperature를 적용하면 분포를 덜 random하게 만들 수 있지만 0으로 설정하면 greedy decoding과 동일해집니다. 그러면 이전과 같은 문제를 다시 겪게 되겠지요.
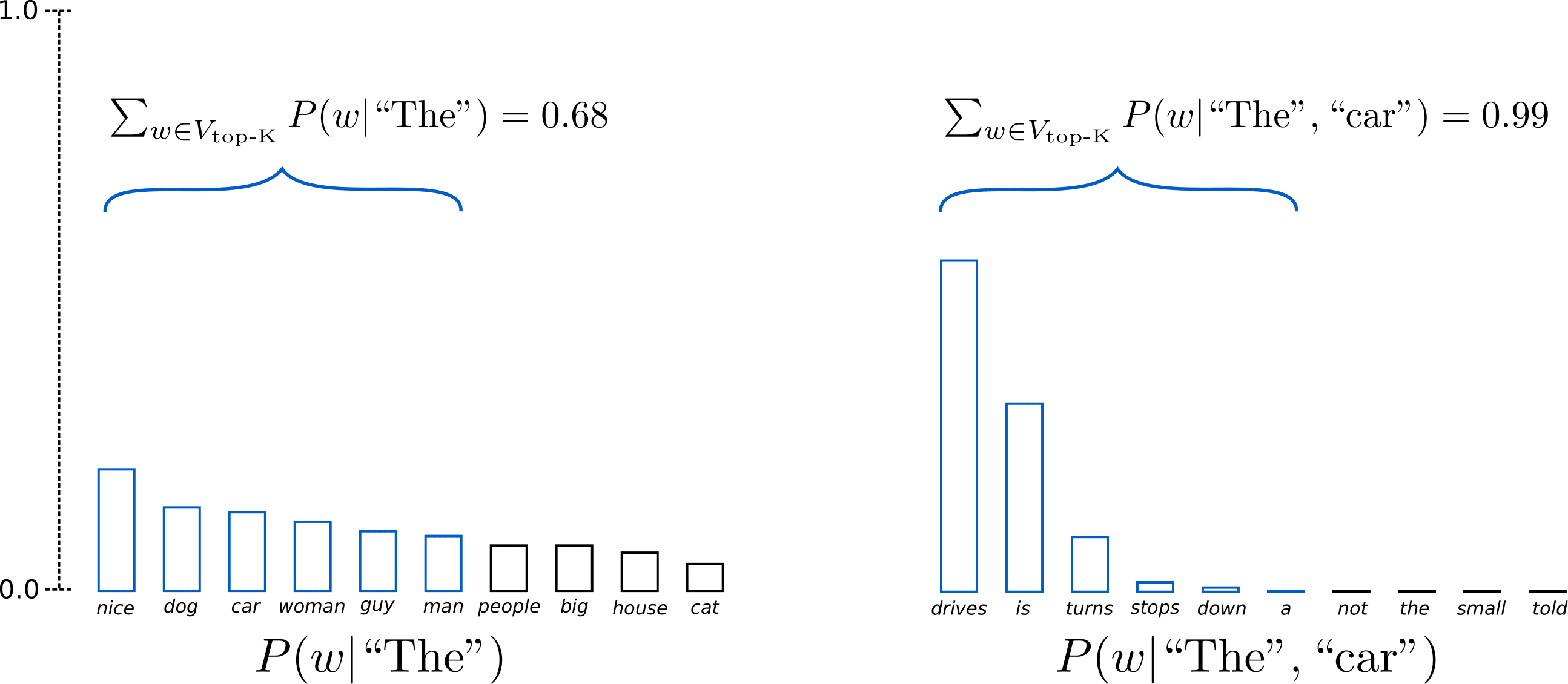
Time step 1에서 Top-6개를 제외한 나머지 people, big, house, cat은 생성 대상에서 제거합니다. (Top-K개만 filtering, Vocab에 pick-up)
Step 1에서는 전체의 2/3, step 2에서는 거의 모든 probability mass를 포함합니다.
Time step 2에서 Top-6개를 제외한 나머지 not, the, small, told 이상한 단어들을 성공적으로 제외하고 추출하는 것을 확인할 수 있습니다.
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=128,
top_k=50,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
제일 괜찮은 결과인 것 같습니다! 가장 인간같이 생성된 것 같군요. Top-K sampling의 한 가지 문제는 next word distribution $P(w|w_{1:t-1})$에서 filtering되는 단어의 수를 dynamic하게 적용하지 않는 다는 점입니다.
- 고정된 K를 사용하기에 문제
위 그래프에서 오른쪽의 경우 매우 sharp한 분포에서 sampling되지만 왼쪽의 경우에는 더 flat한 분포에서 sampling되기에 문제가 될 수 있습니다.
Step 1에서 Top-K는 people, big, house, cat 와 같은 가능성있는 후보군들을 제외했습니다. 반대로 Step 2에서는 단어의 sample pool(In top-k)에 부적합한 단어 down, a를 포함합니다. 때문에 sample pool은 고정된 크기 K로 제한하는 것은 모델이 sharp distribution에 대해 횡설수설(gibberish)할 위험이 있고 flat distribution에 대해 창의성(creativity)이 제한될 수 있습니다.
위 직관이 Ari Holtzman 연구진들이 제안한 Top-p 혹은 nucleus sampling으로 이어집니다.
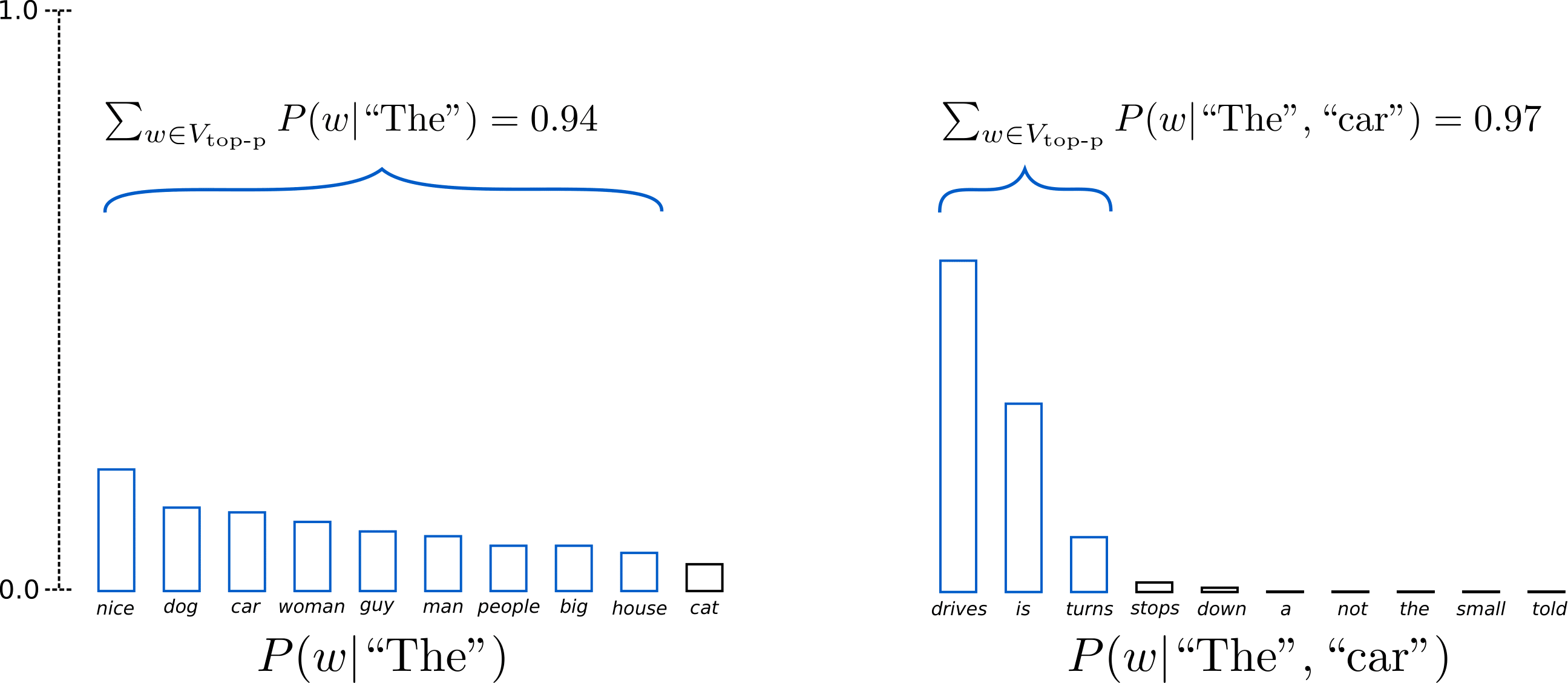
$p=0.92$로 설정하겠습니다. Top-p sampling은 probability mass의 92%를 초과하는 단어의 minimum number를 계산합니다. 이를테면 위에서 cat을 제외한 단어의 prob mass의 합은 0.94로 설정한 p보다 커지게 됩니다. 즉 time step 1에서는 9개의 단어를 고르고 time step 2에서는 drives, is, turns 만으로도 97%입니다. 때문에 3개의 단어로 고정 후 sampling을 수행합니다. Top-K에서 고정적인 K로 sampling한 것과 다르게 Top-p에서는 next word distribution에 따라 dynamic하게 sampling pool을 결정할 수 있습니다.
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=128,
top_p=0.92,
top_k=0,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
좋습니다! 맨 처음 sampling했을 결과보다는 훨씬 더 사람다워 졌습니다. (내용은...)
이론적으로 Top-p는 Top-k보다 더 우아해보이지만 실제로는 두 방법 모두 잘 동작하고 Top-p는 Top-k와 함께 사용할 수 있습니다. Top-K는 매우 낮은 순위의 단어를 피하면서 일부 동적 선택을 허용할 수 있습니다.
마지막으로 독립적으로 샘플링된 여러 출력을 얻기 위해 매개변수 num_return_sequences를 1보다 크게 다시 설정할 수 있습니다.
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=128,
top_p=0.95,
top_k=50,
num_return_sequences=3,
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
decoded_text = tokenizer.decode(sample_output, skip_special_tokens=True)
print(f"{i}: {decoded_text}", end="\n\n")
Conclusion
- top-p, top-k sampling은 open-ended language generation에서 기존의 greedy-and beam search보다 더 유창한 text를 생성하는 것으로 보임
- 최근에 greedy 및 beam search의 명백한 경함(주로 반복적인 word sequence 생성)이 decoding methodology보다는 model(특히 모델이 훈련되는 방식)에 의해 발생한다는 증거가 더 많이 있음.
- 또한 top-k 및 top-p sampling도 repetitive word sequence 생성에서 자유롭진 못하는 것으로 보임
- Welleck의 2019 연구에 의하면 저자는 사람의 평가에 따르면 모델의 훈련 목표를 조정할 때 Beam search가 Top-p sampling보다 더 유창한 text를 생성할 수 있음을 보임
- Open-ended language generation은 빠르게 발전하는 분야이며 여기에 모든 경우에 적용할 수 있는 방법이 없는 경우가 많음. 때문에 특정 사용 사례에 가장 적합한 방법이 무엇인지를 확인해야 한다.
Appendix
위에서 언급하지 않은 생성 메소드에 대한 몇 가지 추가 매개변수 소개
-
min_length: min_lenght에 도달하기 전에 모델이 EOS token을 생성하지 않도록 강제하는 데 사용할 수 있음- 요약에서 매우 자주 사용되지만 사용자가 더 긴 출력을 원할 경우 일반적으로 유용할 수 있음
-
repeat_penalty: 이미 생성되었거나 context에 속하는 단어에 penalty를 적용하는데 사용. Keskar et al., (2019)에 의해 처음으로 소개되었으며 Welleck et al., (2019)의 training objective로도 사용됨. 반복을 방지하는데 매우 효과적일 수 있지만 다양한 모델 및 사용 사례에 매우 민감한 것으로 보임. 해당 디스커션 참고. -
attention_mask: padded token을 mask하는데 사용 -
pad_token_id,bos_token_id,eos_token_id: 모델에 기본적으로 해당 토큰이 없는 경우 사용자는 다른 token id를 수동으로 선택하여 나타낼 수 있음.